Goodfellow Deep Learning — Chapter 9.7: Data Types
Overview
Convolutional networks can operate on many different kinds of data, depending on the number of channels and the dimensionality of the input.
Input Formats
Table 9.1 illustrates how 1D, 2D, and 3D inputs can each appear in both single-channel and multi-channel forms.
 Figure: Examples of different data types CNNs can process. 1D inputs include audio waveforms and time series. 2D inputs include grayscale images (single-channel) and RGB images (multi-channel). 3D inputs correspond to volumes such as CT scans (single-channel) or videos and skeleton animations (multi-channel spatiotemporal data).
Figure: Examples of different data types CNNs can process. 1D inputs include audio waveforms and time series. 2D inputs include grayscale images (single-channel) and RGB images (multi-channel). 3D inputs correspond to volumes such as CT scans (single-channel) or videos and skeleton animations (multi-channel spatiotemporal data).
- 1D inputs include audio waveforms, time series, or multi-sensor signals.
- 2D inputs include grayscale images (single-channel) and RGB or multispectral images (multi-channel).
- 3D inputs correspond to volumes such as CT scans (single-channel) or videos and skeleton animations (multi-channel spatiotemporal data).
Flexibility of Convolution
One advantage of convolution is that it naturally supports these different input structures without requiring a fixed dimensionality or a fixed number of channels.
The same convolutional kernel can be applied across various data types because convolution is fundamentally a translation-equivariant, local operation.
Variable-Sized Inputs
Additionally, convolution can also process variable-sized inputs.
As long as the kernel size is fixed, the convolution operation slides across the input regardless of its spatial extent, producing outputs whose dimensions scale accordingly.
This flexibility enables CNNs to handle inputs with different widths or heights—a property that fully connected networks do not have.
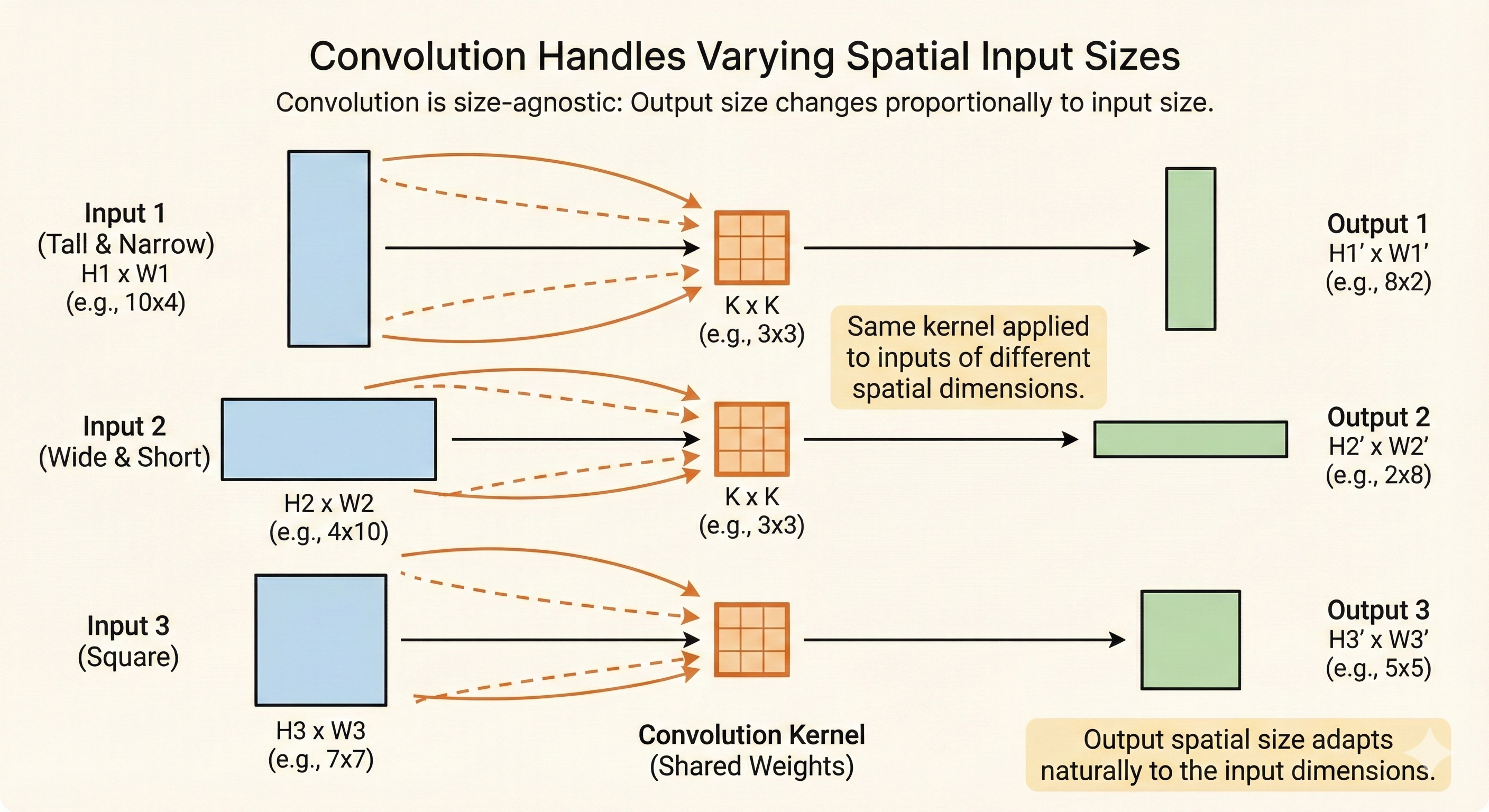 Figure: CNNs can process inputs of different sizes. The same convolutional kernel slides across inputs regardless of spatial extent, producing outputs that scale with the input dimensions. This flexibility is unique to convolutional architectures—fully connected networks require fixed-size inputs.
Figure: CNNs can process inputs of different sizes. The same convolutional kernel slides across inputs regardless of spatial extent, producing outputs that scale with the input dimensions. This flexibility is unique to convolutional architectures—fully connected networks require fixed-size inputs.
Key Insight
The power of CNNs lies in their flexibility. Unlike fully connected networks that require fixed input dimensions, convolutional networks can handle varying channel counts, different spatial dimensionalities (1D, 2D, 3D), and variable-sized inputs—all with the same kernel. This versatility makes CNNs applicable to a wide range of domains beyond computer vision, from audio processing to volumetric medical imaging.