Goodfellow Deep Learning — Chapter 9.6: Structured Outputs
Overview
CNNs can generate high-dimensional structured objects, enabling pixel-level predictions for tasks like segmentation, depth estimation, and flow prediction.
Preserving Spatial Dimensions
To generate pixel-level (full-resolution) outputs, the convolutions must preserve spatial dimensions. This means:
- No pooling layers
- No stride > 1
- Convolution uses SAME padding (e.g., padding=1 for 3×3 kernels)
By maintaining spatial resolution throughout the network, we can produce outputs that match the input dimensions pixel-for-pixel.
Recurrent Convolution
Recurrent convolution repeatedly refines pixel-level predictions by applying the same convolutional transform across time, combining high-resolution input with the previous hidden state to produce increasingly accurate structured outputs.
The Process
The recurrent convolution follows this pattern:
Step 1: \[U * X = H(1), \quad H(1) * V = \hat{Y}(1)\]
Step 2: \[U * X + H(1) * W = H(2), \quad H(2) * V = \hat{Y}(2)\]
Step 3: \[U * X + H(2) * W = H(3), \quad H(3) * V = \hat{Y}(3)\]
Where: - \(U\): Input convolution kernel - \(X\): Input image - \(H(t)\): Hidden state at time \(t\) - \(W\): Recurrent kernel (processes previous hidden state) - \(V\): Output convolution kernel - \(\hat{Y}(t)\): Predicted output at time \(t\)
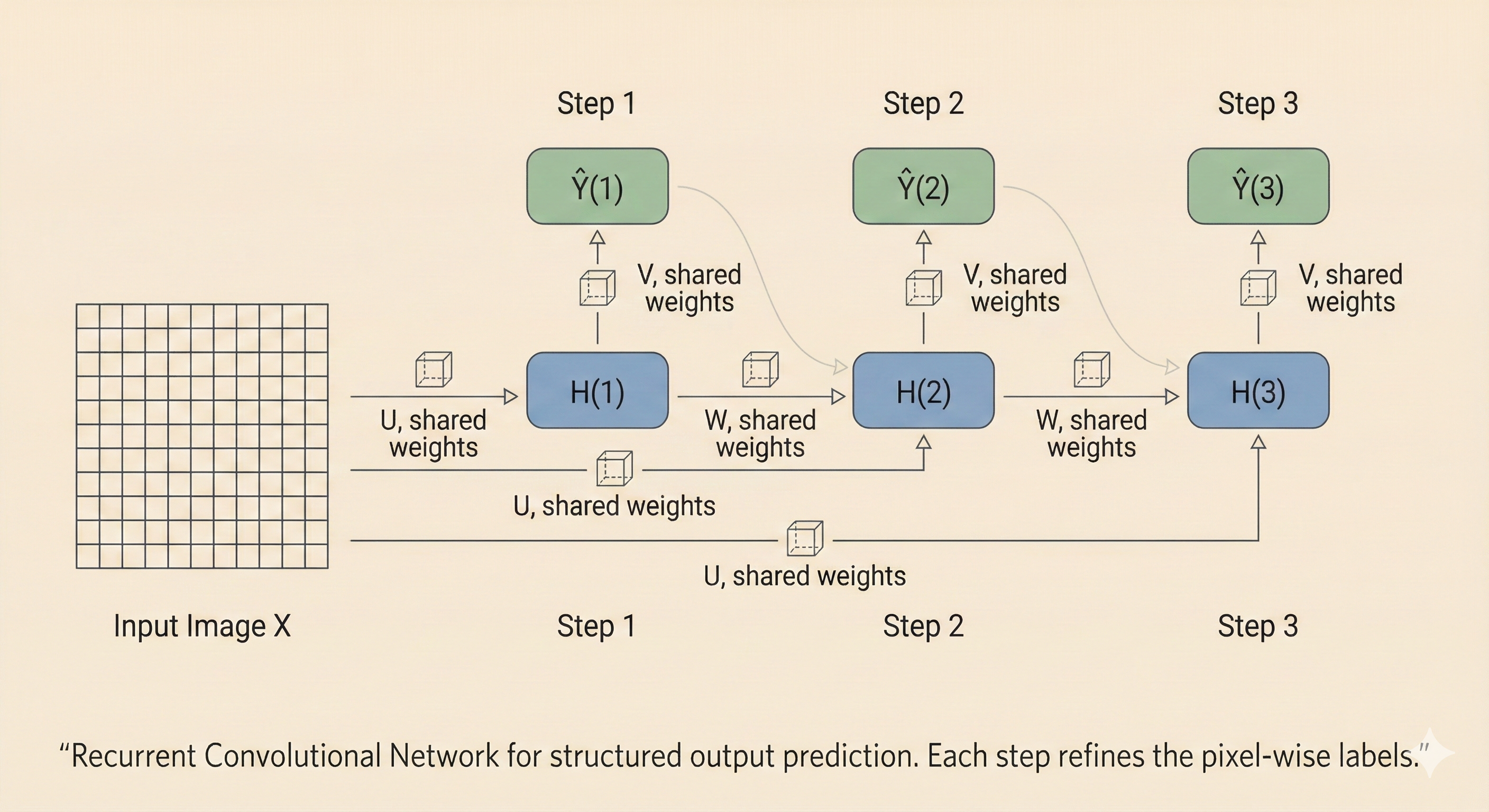 Figure: Recurrent convolution repeatedly refines predictions by combining the input with previous hidden states through convolutional operations.
Figure: Recurrent convolution repeatedly refines predictions by combining the input with previous hidden states through convolutional operations.
Applications: Dense Pixel-Level Predictions
Once a model can produce structured outputs, we can design networks that generate full spatial maps—predicting an entire image-like object rather than a single scalar.
This enables tasks such as:
- Semantic Segmentation: Classifying every pixel into object categories
- Depth Estimation: Predicting distance from camera for each pixel
- Optical Flow Prediction: Estimating motion vectors between frames
- Dense Correspondence: Finding pixel-level matches across images
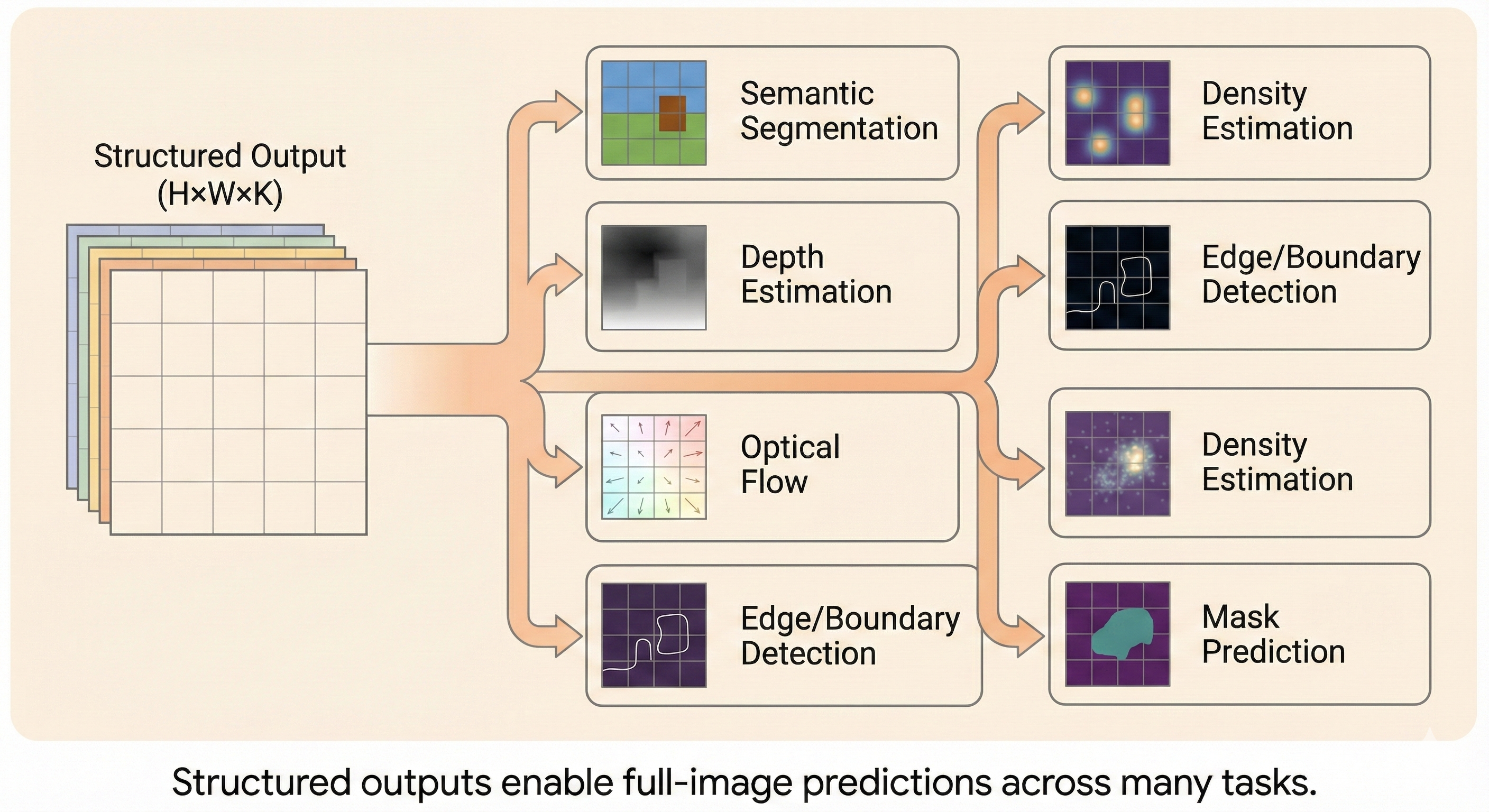 Figure: Examples of structured output tasks where CNNs generate full spatial maps with pixel-level predictions, moving beyond single scalar outputs to dense, coherent predictions.
Figure: Examples of structured output tasks where CNNs generate full spatial maps with pixel-level predictions, moving beyond single scalar outputs to dense, coherent predictions.
Key Insight
The power of structured outputs lies in generating spatially coherent predictions. Rather than treating each output pixel independently, recurrent convolution allows information to flow across the spatial map, ensuring that neighboring predictions are consistent and that the network can refine its outputs iteratively based on context from the entire image.