Goodfellow Deep Learning — Chapter 10.4: Encoder-Decoder Sequence-to-Sequence Architecture
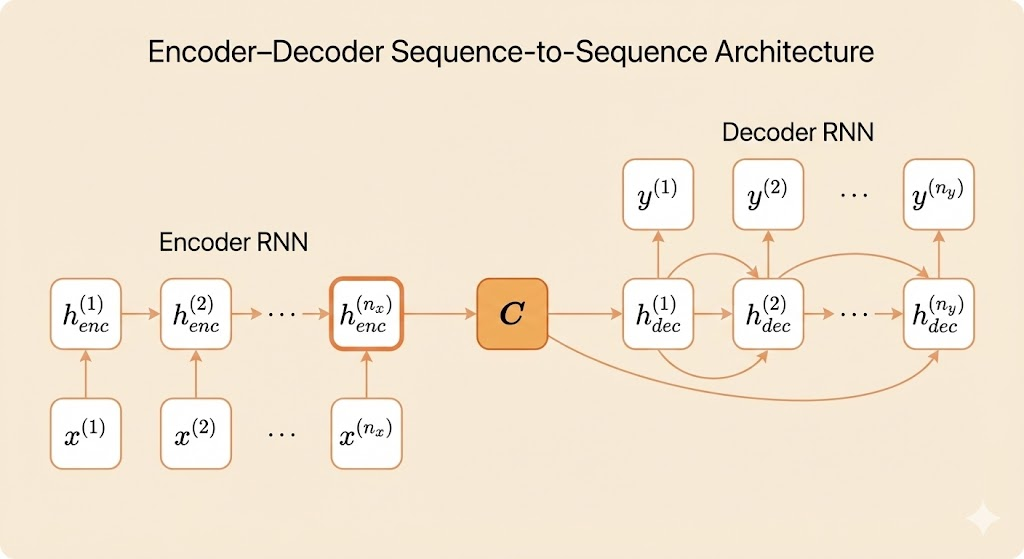
The encoder–decoder (seq2seq) architecture was introduced to model conditional sequence distributions where the input and output sequences may have different lengths and different semantic roles. This generalizes earlier RNN architectures, which assumed a one-to-one correspondence between input and output over time \((i.e., n_x = n_y = \tau).\)
1. Encoder
The encoder RNN reads the entire input sequence \[x^{(1)}, x^{(2)}, \dots, x^{(n_x)},\] and gradually compresses all information into a fixed-dimensional context vector: \[C = \text{Encoder}(x^{(1:n_x)}).\] This context vector represents the input sequence as a single summary embedding.
2. Decoder
The decoder RNN takes the context vector C and generates the output sequence \[y^{(1)}, y^{(2)}, \dots, y^{(n_y)},\] one step at a time.
At each time step, the decoder conditions on: - the context vector C - the previous outputs \(y^{(1:t-1)}\) (teacher forcing during training)
Thus the conditional distribution over the output is: \[P(Y \mid X) = \prod_{t=1}^{n_y} P\big(y^{(t)} \mid y^{(1:t-1)},\, C\big).\]
3. Training Objective
The encoder and decoder are trained jointly to maximize the conditional log-likelihood: \[\log P\big(y^{(1)}, \dots, y^{(n_y)} \mid x^{(1)}, \dots, x^{(n_x)}\big).\] This formulation places no restriction on the relationship between \(n_x\) and \(n_y\), enabling flexible sequence transformation.
The encoder–decoder framework enables RNNs to address problems where: - input length ≠ output length - temporal alignment is unknown - outputs depend on both the entire input and previously generated outputs
This architecture is the foundation for many key applications, such as: - machine translation - summarization - dialogue generation - image captioning (when combined with CNN encoders)
It also forms the conceptual basis for the later development of attention mechanisms.