Goodfellow Deep Learning — Chapter 9.10: Neuroscientific Basis for Convolutional Networks
V1: Primary Visual Cortex
V1 is a part of the brain, also named as the primary visual cortex. It exhibits three key properties that inspired convolutional neural networks:
- Spatial mapping: Neurons in V1 form a topographic map of the visual field
- Simple cells: Detect features within local receptive fields
- Complex cells: Exhibit translation invariance
 Figure: The primary visual cortex (V1) contains simple cells with local receptive fields that detect oriented edges, and complex cells that pool over simple cells to achieve translation invariance—inspiring the convolution and pooling operations in CNNs.
Figure: The primary visual cortex (V1) contains simple cells with local receptive fields that detect oriented edges, and complex cells that pool over simple cells to achieve translation invariance—inspiring the convolution and pooling operations in CNNs.
Grandmother Cell
The grandmother cell is a classic (and partly humorous) idea in neuroscience suggesting that a single neuron might respond exclusively to a very specific concept—such as your grandmother’s face and nothing else.
Although this extreme form of representation is unlikely to exist exactly as described, experiments have revealed highly selective neurons in the human medial temporal lobe, such as the famous “Jennifer Aniston neuron”, which respond strongly to one particular person or concept across different images and modalities.
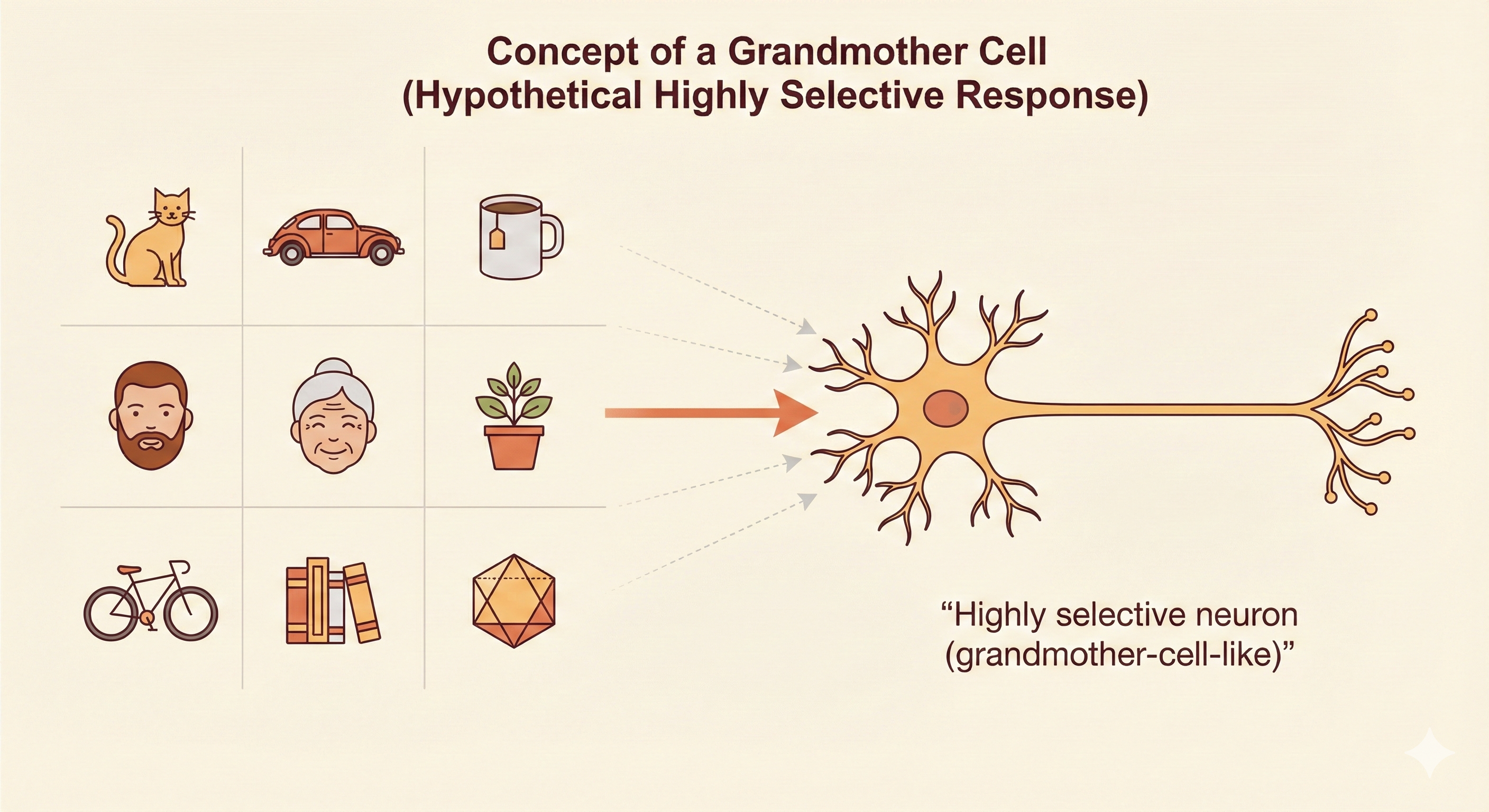 Figure: The “grandmother cell” hypothesis: highly selective neurons that respond to specific concepts or people. While extreme single-neuron selectivity is rare, the Jennifer Aniston neuron demonstrates that some neurons can be remarkably selective for particular individuals.
Figure: The “grandmother cell” hypothesis: highly selective neurons that respond to specific concepts or people. While extreme single-neuron selectivity is rare, the Jennifer Aniston neuron demonstrates that some neurons can be remarkably selective for particular individuals.
Differences Between CNNs and Animal Vision Systems
1. Retinal Resolution and Saccades
The human eye has very low resolution over most of the visual field, except for a small high-resolution region called the fovea. In contrast, most CNNs receive uniformly high-resolution images as input.
To compensate for the retina’s limited resolution, the brain performs rapid eye movements called saccades, selectively directing the fovea toward the most informative or task-relevant parts of the scene. The brain then integrates these glimpses into a coherent perception.
This biological mechanism closely relates to modern attention mechanisms in deep learning, which dynamically focus computation on informative regions rather than processing every pixel uniformly.
2. Global Scene Understanding
Animal vision does not merely recognize isolated objects—it constructs an understanding of the entire scene, including relationships between objects, their spatial layout, depth cues, and how everything interacts with the body’s position in 3-D space.
CNNs, however, operate primarily as object recognizers trained on static images. They lack the integrated multi-modal processing found in biological systems, such as combining vision with touch, motion, memory, and expectation. As a result, CNNs often fail on tasks that require holistic scene reasoning, contextual interpretation, or understanding how objects interact in physical environments.
3. Multisensory Integration (Vision + Auditory System)
The human visual system operates in tight coordination with other sensory systems, especially hearing. Visual perception is continuously influenced by auditory cues—such as detecting motion from sound, inferring object properties, or resolving ambiguity when visual information is incomplete.
4. Strong Top-Down Feedback in Biological Vision
Even early visual areas like V1 receive significant top-down feedback from higher cortical regions (V2, V4, IT, PFC). This feedback modulates attention, context interpretation, and perceptual expectations. Most CNNs rely on purely feed-forward processing with limited or no feedback mechanisms.
5. V1 Receptive Fields Are Gabor-like but More Complex
While many V1 neurons resemble Gabor filters, their actual responses are more dynamic and context-dependent. CNN filters are fixed, static linear kernels, whereas biological receptive fields adapt to stimuli, feedback, and behavioral state. Thus CNN filter banks are only an approximation of biological V1.
Gabor Function and Simple Cells
Simple cells in V1 can be modeled by a response function that computes a weighted sum over the image:
\[ S(I) = \sum_{x \in X} \sum_{y \in Y} w(x,y) I(x,y) \tag{9.15} \]
where \(w(x,y)\) takes the form of a Gabor function:
\[ w(x,y;\alpha,\beta_x,\beta_y,f,\phi,x_0,y_0,\tau) = \alpha \exp(-\beta_x x'^2 - \beta_y y'^2) \cos(fx' + \phi) \tag{9.16} \]
with rotated coordinates:
\[ x' = (x - x_0) \cos(\tau) + (y - y_0) \sin(\tau) \tag{9.17} \]
\[ y' = -(x - x_0) \sin(\tau) + (y - y_0) \cos(\tau) \tag{9.18} \]
Gabor Function Parameters
- \(x_0, y_0\) — Receptive field center: Specifies where the filter is located on the image plane
- \(\tau\) — Orientation angle: Defines the preferred edge orientation of the simple cell
- \(\beta_x, \beta_y\) — Gaussian width parameters: Control the shape and spatial extent of the receptive field
- \(f\) — Spatial frequency: Determines how many cycles of the cosine grating appear within the receptive field (higher \(f\) detects finer edges)
- \(\phi\) — Phase offset: Controls whether the cell responds to dark-to-light edges, light-to-dark edges, or symmetric patterns
- \(\alpha\) — Amplitude scaling: Controls the overall response magnitude
Together, these parameters determine a simple cell’s preferred position, orientation, spatial frequency, and phase, allowing the Gabor function to closely approximate the tuning properties observed in biological V1 neurons.
 Figure: Gabor filters model V1 simple cells. The parameters (position, orientation, frequency, phase) define a simple cell’s selectivity for specific edge patterns at particular locations and orientations in the visual field.
Figure: Gabor filters model V1 simple cells. The parameters (position, orientation, frequency, phase) define a simple cell’s selectivity for specific edge patterns at particular locations and orientations in the visual field.
Complex Cells and Pooling
Complex cells combine the outputs of several simple cells that share the same orientation and spatial frequency but differ in phase. By pooling this quadrature pair of simple cells, complex cells become phase-invariant—they respond to an oriented edge regardless of small shifts, contrast polarity, or phase changes.
This gives them local translation invariance, and similar behavior emerges in machine learning through pooling operations over Gabor-like filters.
Key Insight
CNNs draw deep inspiration from V1, but biological vision is far richer and more complex. Simple cells act like Gabor filters, detecting oriented edges at specific locations. Complex cells pool over simple cells to achieve translation invariance, mirroring CNN pooling layers. However, CNNs lack key features of biological vision: saccadic attention, multisensory integration, top-down feedback, and dynamic receptive fields. While CNNs excel at feed-forward object recognition, they remain far from the holistic, context-aware, adaptive processing that characterizes animal vision systems. Understanding these differences guides future architectures toward more biologically plausible and robust visual intelligence.